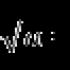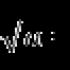1 واریانس را تعیین کنید. نرخ های تغییر مطلق
پراکندگی در آماربه عنوان مقادیر فردی ویژگی در مربع یافت می شود. بسته به داده های اولیه، با فرمول های واریانس ساده و وزنی تعیین می شود:
1. (برای داده های گروه بندی نشده) با فرمول محاسبه می شود:
2. واریانس وزنی (برای یک سری تغییرات):
 جایی که n فرکانس است (ضریب تکرارپذیری X)
جایی که n فرکانس است (ضریب تکرارپذیری X)
نمونه ای از یافتن واریانس
این صفحه یک مثال استاندارد از یافتن واریانس را توضیح می دهد، همچنین می توانید برای یافتن آن به کارهای دیگر نگاه کنید
مثال 1. ما داده های زیر را برای یک گروه 20 دانش آموز داریم بخش مکاتبات. نیاز به ساختن سری بازه ایتوزیع ویژگی، محاسبه مقدار میانگین ویژگی و مطالعه واریانس آن
 بیایید یک گروه بندی فاصله بسازیم. بیایید محدوده بازه را با فرمول تعیین کنیم:
بیایید یک گروه بندی فاصله بسازیم. بیایید محدوده بازه را با فرمول تعیین کنیم:
![]() که در آن X max حداکثر مقدار ویژگی گروه بندی است.
که در آن X max حداکثر مقدار ویژگی گروه بندی است.
Xmin حداقل مقدار ویژگی گروه بندی است.
n تعداد فواصل است:
ما n=5 را می پذیریم. مرحله این است: h \u003d (192 - 159) / 5 \u003d 6.6
بیایید یک گروه بندی فاصله ای ایجاد کنیم
 برای محاسبات بیشتر، یک جدول کمکی می سازیم:
برای محاسبات بیشتر، یک جدول کمکی می سازیم:
 X'i وسط فاصله است. (به عنوان مثال، وسط فاصله 159 - 165.6 = 162.3)
X'i وسط فاصله است. (به عنوان مثال، وسط فاصله 159 - 165.6 = 162.3)
میانگین رشد دانش آموزان با فرمول میانگین موزون حسابی تعیین می شود:
 ما پراکندگی را با فرمول تعیین می کنیم:
ما پراکندگی را با فرمول تعیین می کنیم:
فرمول واریانس را می توان به صورت زیر تبدیل کرد:

از این فرمول نتیجه می شود که واریانس است تفاوت بین میانگین مربع های گزینه ها و مربع و میانگین.
پراکندگی در سری تغییرات با فواصل مساوی با توجه به روش گشتاورها را می توان به روش زیر با استفاده از خاصیت پراکندگی دوم (تقسیم همه گزینه ها بر مقدار بازه) محاسبه کرد. تعریف واریانسمحاسبه شده به روش ممان، طبق فرمول زیر زمان کمتری دارد:

جایی که i مقدار بازه است.
الف - صفر مشروط، که برای استفاده از وسط بازه با بالاترین فرکانس راحت است.
m1 مربع ممان مرتبه اول است.
m2 - لحظه سفارش دوم
(اگر در جامعه آماری ویژگی به گونه ای تغییر کند که تنها دو گزینه متقابل وجود داشته باشد، آنگاه چنین متغیری جایگزین نامیده می شود) را می توان با فرمول محاسبه کرد:

تعویض در این فرمولپراکندگی q \u003d 1- p، دریافت می کنیم:

انواع پراکندگی
واریانس کلتغییرات یک صفت را در کل جمعیت به عنوان یک کل تحت تأثیر همه عواملی که باعث این تنوع می شوند اندازه گیری می کند. این برابر است با میانگین مربع انحراف مقادیر فردی ویژگی x از مقدار متوسط کل x و می تواند به عنوان واریانس ساده یا واریانس وزنی تعریف شود.
تغییرات تصادفی را مشخص می کند، یعنی. بخشی از تغییرات، که به دلیل تأثیر عوامل نامشخص است و به عامل علامت زیربنای گروه بندی بستگی ندارد. این واریانس برابر است با میانگین مجذور انحراف مقادیر فردی صفت در گروه X از میانگین حسابی گروه و می تواند به عنوان یک واریانس ساده یا به عنوان واریانس وزنی محاسبه شود.
به این ترتیب، اندازه گیری های واریانس درون گروهیتنوع یک صفت در یک گروه و با فرمول تعیین می شود:

جایی که xi - میانگین گروه.
ni تعداد واحدهای گروه است.
برای مثال، واریانسهای درون گروهی، که باید در کار مطالعه تأثیر شایستگیهای کارگران بر سطح بهرهوری نیروی کار در مغازه تعیین شوند، تغییراتی را در تولید در هر گروه نشان میدهند که ناشی از همه عوامل احتمالی (شرایط فنیتجهیزات، در دسترس بودن ابزار و مواد، سن کارگران، شدت کار، و غیره)، به جز تفاوت در رده صلاحیت (در گروه، همه کارگران دارای صلاحیت های یکسان هستند).
میانگین واریانس های درون گروهی منعکس کننده تصادفی، یعنی آن بخشی از تغییرات است که تحت تأثیر همه عوامل دیگر، به استثنای عامل گروه بندی، رخ داده است. با فرمول محاسبه می شود:

این تنوع سیستماتیک صفت حاصل را مشخص می کند که به دلیل تأثیر عامل صفت زیربنایی گروه بندی است. برابر است با مجذور میانگین انحراف میانگین های گروه از میانگین کلی. واریانس بین گروهی با فرمول محاسبه می شود:

قانون جمع واریانس در آمار
مطابق با قانون جمع واریانس واریانس کلبرابر است با مجموع میانگین پراکندگی درون گروهی و بین گروهی:
![]()
معنی این قاعدهاین است که واریانس کل که تحت تأثیر همه عوامل رخ می دهد برابر است با مجموع واریانس هایی که تحت تأثیر همه عوامل دیگر ایجاد می شود و واریانسی که به دلیل عامل گروه بندی ایجاد می شود.
با استفاده از فرمول اضافه کردن واریانس ها، می توان مجهول سوم را از دو واریانس شناخته شده تعیین کرد و همچنین قدرت تأثیر ویژگی گروه بندی را قضاوت کرد.
خواص پراکندگی
1. اگر همه مقادیر مشخصه با همان مقدار ثابت کاهش (افزایش) شود، واریانس از این تغییر نخواهد کرد.
2. اگر تمام مقادیر مشخصه به همان تعداد n کاهش (افزایش) شود، بر این اساس واریانس n^2 برابر کاهش (افزایش) خواهد شد.
پراکندگیمتغیر تصادفی- اندازه گیری پراکندگی یک داده متغیر تصادفی، یعنی او انحرافاتاز جانب انتظارات ریاضی. در آمار، نماد (سیگما مربع) اغلب برای نشان دادن واریانس استفاده می شود. جذر واریانس نامیده می شود انحراف معیاریا پخش استاندارد انحراف استاندارد با واحدهای مشابه اندازه گیری می شود مقدار تصادفی، و واریانس در مربع های آن واحد اندازه گیری می شود.
اگرچه استفاده از تنها یک مقدار (مانند میانگین یا حالت و میانه) برای تخمین کل نمونه بسیار راحت است، این رویکرد به راحتی می تواند به نتیجه گیری های نادرست منجر شود. دلیل این وضعیت در خود مقدار نیست، بلکه در این واقعیت است که یک مقدار به هیچ وجه منعکس کننده گسترش مقادیر داده نیست.
به عنوان مثال، در نمونه:
میانگین 5 است.
با این حال، هیچ عنصری در خود نمونه با مقدار 5 وجود ندارد. ممکن است لازم باشد بدانید که هر عنصر از نمونه چقدر به مقدار میانگین خود نزدیک است. یا به عبارت دیگر، باید واریانس مقادیر را بدانید. با دانستن میزان تغییر داده ها، می توانید بهتر تفسیر کنید منظور داشتن, میانهو روش. درجه تغییر در مقادیر نمونه با محاسبه واریانس و انحراف معیار آنها تعیین می شود.
پراکندگی و ریشه دوماز واریانس، که انحراف معیار نامیده می شود، میانگین انحراف از میانگین نمونه را مشخص می کند. در میان این دو کمیت، مهمترین آن است انحراف معیار . این مقدار را می توان به عنوان فاصله متوسطی که عناصر از عنصر میانی نمونه قرار دارند نشان داد.
تفسیر معنادار پراکندگی دشوار است. با این حال، جذر این مقدار انحراف معیار است و به خوبی به تفسیر کمک می کند.
انحراف معیار ابتدا با تعیین واریانس و سپس محاسبه جذر واریانس محاسبه می شود.
به عنوان مثال، برای آرایه داده نشان داده شده در شکل، مقادیر زیر به دست می آید:

تصویر 1
در اینجا، میانگین اختلاف مجذور 717.43 است. برای به دست آوردن انحراف معیار، فقط باید جذر این عدد را بگیرید.
نتیجه تقریباً 26.78 خواهد بود.
باید به خاطر داشت که انحراف استاندارد به عنوان فاصله متوسطی که عناصر از میانگین نمونه قرار دارند تفسیر می شود.
انحراف معیار نشان می دهد که میانگین چقدر کل نمونه را توصیف می کند.
فرض کنید شما مدیر هستید بخش تولیدمونتاژ کامپیوتر. گزارش سه ماهه می گوید که خروجی در سه ماهه گذشته 2500 رایانه شخصی بوده است. بد است یا خوب؟ شما خواسته اید (یا قبلاً این ستون در گزارش وجود دارد) انحراف استاندارد برای این داده ها در گزارش نمایش داده شود. به عنوان مثال، عدد انحراف استاندارد 2000 است. برای شما به عنوان رئیس بخش مشخص می شود که خط تولید به کنترل بهتری نیاز دارد (انحرافات بسیار زیاد در تعداد رایانه های شخصی در حال مونتاژ).
یادمان باشد: چه زمانی سایز بزرگاگر انحراف معیار خیلی کم باشد، داده ها به طور گسترده در اطراف میانگین پراکنده می شوند و اگر انحراف استاندارد کم باشد، آنها نزدیک به میانگین خوشه بندی می شوند.
چهار تابع آماری VARP()، VARP()، STDEV() و STDEV() برای محاسبه واریانس و انحراف استاندارد اعداد در محدوده ای از سلول ها طراحی شده اند. قبل از اینکه بتوانید واریانس و انحراف معیار یک مجموعه داده را محاسبه کنید، باید تعیین کنید که آیا داده ها نشان دهنده جامعه هستند یا نمونه ای از جامعه. در مورد نمونه ای از جمعیت عمومی، باید از توابع VARP() و STDEV() و در مورد جمعیت عمومی، از توابع VARP() و STDEV() استفاده شود:
| جمعیت | عملکرد |
 | VARP() |
 | STDLONG() |
| نمونه | |
 | VARI() |
 | STDEV() |
واریانس (و همچنین انحراف استاندارد)، همانطور که اشاره کردیم، میزان پراکندگی مقادیر موجود در مجموعه داده ها را در اطراف میانگین حسابی نشان می دهد.
مقدار کمی از واریانس یا انحراف معیار نشان می دهد که تمام داده ها حول میانگین حسابی متمرکز شده اند و پراهمیتاین مقادیر - که داده ها در طیف گسترده ای از مقادیر پراکنده شده اند.
تفسیر معنادار واریانس نسبتاً دشوار است (معنی یک مقدار کوچک، یک مقدار بزرگ چیست؟). کارایی وظایف 3به شما این امکان را می دهد که به صورت بصری، در یک نمودار، معنای واریانس یک مجموعه داده را نشان دهید.
وظایف
· تمرین 1.
· 2.1. مفاهیم: واریانس و انحراف معیار را بیان کنید. نام نمادین آنها در پردازش داده های آماری.
· 2.2. مطابق شکل 1 یک کاربرگ تهیه کنید و محاسبات لازم را انجام دهید.
· 2.3. فرمول های اصلی مورد استفاده در محاسبات را بیان کنید
· 2.4. تمام نمادهای ( , , ) را توضیح دهید
· 2.5. توضیح ارزش عملیمفاهیم واریانس و انحراف معیار
وظیفه 2.
1.1. مفاهیم را بیان کنید: جمعیت عمومی و نمونه. انتظارات ریاضی و میانگین حسابی تعیین نمادین آنها در پردازش داده های آماری.
1.2. مطابق شکل 2، یک کاربرگ تهیه کنید و محاسبات را انجام دهید.
1.3. فرمول های اساسی مورد استفاده در محاسبات (برای جمعیت عمومی و نمونه) را بیان کنید.

شکل 2
1.4. توضیح دهید که چرا می توان مقادیری از میانگین های حسابی را در نمونه هایی مانند 46.43 و 48.78 به دست آورد (به فایل پیوست مراجعه کنید). نتیجه گیری.
وظیفه 3.
دو نمونه با مجموعه متفاوتداده ها، اما میانگین آنها یکسان خواهد بود:

شکل 3
3.1. مطابق شکل 3 یک کاربرگ تهیه کرده و محاسبات لازم را انجام دهید.
3.2. فرمول های محاسباتی اولیه را ارائه دهید.
3.3. نمودارها را مطابق شکل های 4 و 5 بسازید.
3.4. وابستگی های حاصل را توضیح دهید.
3.5. محاسبات مشابهی را برای این دو نمونه انجام دهید.
نمونه اولیه 11119999
مقادیر نمونه دوم را طوری انتخاب کنید که میانگین حسابی نمونه دوم یکسان باشد، به عنوان مثال:

مقادیر نمونه دوم را خودتان انتخاب کنید. محاسبات را مرتب کنید و مانند شکل های 3، 4، 5 ترسیم کنید. فرمول های اصلی را که در محاسبات استفاده شده است نشان دهید.
نتیجه گیری مناسب را انجام دهید.
کلیه وظایف باید در قالب یک گزارش همراه با تمام شکل ها، نمودارها، فرمول ها و توضیحات مختصر ارائه شود.
نکته: ساخت نمودارها باید با شکل و توضیحات مختصر توضیح داده شود.
در میان بسیاری از شاخص هایی که در آمار استفاده می شود، لازم است محاسبه واریانس برجسته شود. لازم به ذکر است که انجام دستی این محاسبه یک کار نسبتا خسته کننده است. خوشبختانه، توابعی در اکسل وجود دارد که به شما امکان می دهد روش محاسبه را خودکار کنید. بیایید الگوریتم کار با این ابزارها را دریابیم.
پراکندگی نشانگر تغییرات است که مجذور میانگین انحرافات از انتظارات ریاضی است. بنابراین، گسترش اعداد در مورد میانگین را بیان می کند. محاسبه پراکندگی هم برای جمعیت عمومی و هم برای نمونه قابل انجام است.
روش 1: محاسبه بر روی جمعیت عمومی
برای محاسبه این اندیکاتور در اکسل برای عموم مردم از تابع استفاده می شود DISP.G. نحو این عبارت به شرح زیر است:
DISP.G(Number1; Number2;…)
در مجموع، از 1 تا 255 آرگومان قابل اعمال است. آرگومان ها می توانند هم مقادیر عددی باشند و هم ارجاع به سلول هایی که در آنها قرار دارند.
بیایید ببینیم چگونه این مقدار را برای طیف وسیعی از داده های عددی محاسبه کنیم.


روش 2: محاسبه نمونه
بر خلاف محاسبه مقدار برای جمعیت عمومی، در محاسبه برای نمونه، مخرج تعداد کل اعداد نیست، بلکه یک عدد کمتر است. این کار به منظور اصلاح خطا انجام می شود. اکسل این تفاوت های ظریف را در یک تابع ویژه که برای این نوع محاسبه طراحی شده است - DISP.V در نظر می گیرد. نحو آن با فرمول زیر نمایش داده می شود:
VAR.B (شماره 1؛ شماره 2؛…)
تعداد آرگومان ها، مانند تابع قبلی، می تواند از 1 تا 255 متغیر باشد.


همانطور که می بینید، برنامه اکسل قادر است تا حد زیادی محاسبه واریانس را تسهیل کند. این آمار را می توان هم برای جامعه و هم برای نمونه توسط برنامه محاسبه کرد. در این حالت، تمام اقدامات کاربر در واقع تنها به تعیین محدوده اعداد مورد پردازش کاهش می یابد و اکسل کار اصلی را خود انجام می دهد. البته این امر باعث صرفه جویی قابل توجهی در زمان کاربران خواهد شد.
پراکندگی معیاری از پراکندگی است که انحراف نسبی بین مقادیر داده و میانگین را توصیف می کند. این معیار پرکاربردترین معیار پراکندگی در آمار است که با جمع، مجذور، انحراف هر مقدار داده از سایز متوسط. فرمول محاسبه واریانس در زیر نشان داده شده است:
![]()
s 2 - واریانس نمونه;
x cf مقدار میانگین نمونه است.
n — اندازه نمونه (تعداد مقادیر داده)،
(x i – x cf) انحراف از مقدار میانگین برای هر مقدار از مجموعه داده است.
برای درک بهتر فرمول، اجازه دهید به یک مثال نگاه کنیم. من واقعا آشپزی را دوست ندارم، بنابراین به ندرت آن را انجام می دهم. با این حال، برای اینکه از گرسنگی نمردم، هر از گاهی مجبور می شوم برای اجرای طرح اشباع بدنم از پروتئین، چربی و کربوهیدرات، به اجاق گاز بروم. مجموعه داده های زیر نشان می دهد که رنات هر ماه چند بار غذا می پزد:
اولین مرحله در محاسبه واریانس، تعیین میانگین نمونه است که در مثال ما 7.8 بار در ماه است. محاسبات باقی مانده را می توان با کمک جدول زیر تسهیل کرد.

مرحله نهایی محاسبه واریانس به صورت زیر است:
![]()
برای کسانی که دوست دارند تمام محاسبات را یکجا انجام دهند، معادله به این صورت خواهد بود:
استفاده از روش شمارش خام (مثال آشپزی)
باز هم هست روش موثرمحاسبه واریانس که به روش "شمارش خام" معروف است. اگرچه در نگاه اول ممکن است این معادله کاملاً دست و پا گیر به نظر برسد، اما در واقع آنقدرها هم ترسناک نیست. شما می توانید این را تأیید کنید، و سپس تصمیم بگیرید که کدام روش را بیشتر دوست دارید.

مجموع هر مقدار داده پس از مربع کردن است،
مجذور مجموع همه مقادیر داده است.
فعلا عقلت رو از دست نده بیایید همه را در قالب یک جدول قرار دهیم و سپس خواهید دید که در اینجا محاسبات کمتری نسبت به مثال قبلی وجود دارد.


همانطور که می بینید، نتیجه همان روش استفاده از روش قبلی است. مزایای این روش با افزایش حجم نمونه (n) آشکار می شود.
محاسبه واریانس در اکسل
همانطور که احتمالاً قبلاً حدس زده اید، اکسل فرمولی دارد که به شما امکان می دهد واریانس را محاسبه کنید. علاوه بر این، با شروع از اکسل 2010، می توانید 4 نوع فرمول پراکندگی را پیدا کنید:
1) VAR.V - واریانس نمونه را برمی گرداند. مقادیر بولی و متن نادیده گرفته می شوند.
2) VAR.G - واریانس جمعیت را برمیگرداند. مقادیر بولی و متن نادیده گرفته می شوند.
3) VASP - واریانس نمونه را با در نظر گرفتن مقادیر بولی و متنی برمیگرداند.
4) VARP - واریانس جمعیت را با در نظر گرفتن مقادیر منطقی و متنی برمیگرداند.
ابتدا، اجازه دهید تفاوت بین یک نمونه و یک جامعه را بررسی کنیم. هدف از آمار توصیفی، خلاصه کردن یا نمایش داده ها به گونه ای است که به سرعت یک تصویر بزرگ، به اصطلاح، یک نمای کلی به دست آید. استنتاج آماری به شما این امکان را می دهد که بر اساس نمونه ای از داده های این جامعه استنباط هایی در مورد یک جمعیت انجام دهید. جمعیت نشان دهنده تمام نتایج یا اندازه گیری های ممکن است که مورد علاقه ما هستند. نمونه زیر مجموعه ای از یک جامعه است.
به عنوان مثال، ما به مجموع یک گروه از دانش آموزان یکی از علاقه مندیم دانشگاه های روسیهو باید میانگین امتیاز گروه را مشخص کنیم. میتوانیم میانگین عملکرد دانشآموزان را محاسبه کنیم، و سپس رقم بهدستآمده یک پارامتر خواهد بود، زیرا کل جمعیت در محاسبات ما دخیل خواهند بود. اما اگر بخواهیم معدل کل دانش آموزان کشورمان را محاسبه کنیم، این گروه نمونه ما خواهد بود.
تفاوت در فرمول محاسبه واریانس بین نمونه و جامعه در مخرج است. جایی که برای نمونه برابر با (n-1) و برای جمعیت عمومی فقط n خواهد بود.
حال به توابع محاسبه واریانس با پایان می پردازیم آ،که در توضیح آن گفته شده است که محاسبه متن و مقادیر منطقی را در نظر می گیرد. در این حالت، هنگام محاسبه واریانس یک مجموعه داده خاص که در آن مقادیر غیر عددی رخ میدهند، اکسل متن و بولیهای نادرست را 0 و بولیهای واقعی را 1 تفسیر میکند.
بنابراین، اگر آرایه ای از داده ها دارید، محاسبه واریانس آن با استفاده از یکی از توابع اکسل ذکر شده در بالا دشوار نخواهد بود.

 .
.
برعکس، اگر یک a.e غیر منفی است. تابعی به گونه ای که  ، پس یک اندازه گیری احتمال کاملاً پیوسته بر روی آن وجود دارد که چگالی آن است.
، پس یک اندازه گیری احتمال کاملاً پیوسته بر روی آن وجود دارد که چگالی آن است.
تغییر اندازه در انتگرال Lebesgue:
 ,
,
هر تابع Borel با توجه به اندازه گیری احتمال ادغام پذیر است.
پراکندگی، انواع و خواص پراکندگی مفهوم پراکندگی
پراکندگی در آماربه عنوان انحراف معیار مقادیر فردی صفت مجذور میانگین حسابی یافت می شود. بسته به داده های اولیه، با فرمول های واریانس ساده و وزنی تعیین می شود:
1. واریانس ساده(برای داده های گروه بندی نشده) با فرمول محاسبه می شود:
![]()
2. واریانس وزنی (برای یک سری تغییرات):

جایی که n - فرکانس (ضریب تکرارپذیری X)
نمونه ای از یافتن واریانس
این صفحه یک مثال استاندارد از یافتن واریانس را توضیح می دهد، همچنین می توانید برای یافتن آن به کارهای دیگر نگاه کنید
مثال 1. تعیین گروه، میانگین گروه، بین گروه و واریانس کل
مثال 2. یافتن واریانس و ضریب تغییرات در جدول گروه بندی
مثال 3. یافتن واریانس در یک سری گسسته
مثال 4. ما داده های زیر را برای یک گروه 20 دانشجوی مکاتبه ای داریم. ساخت یک سری بازه ای از توزیع ویژگی، محاسبه مقدار میانگین ویژگی و مطالعه واریانس آن ضروری است.

بیایید یک گروه بندی فاصله بسازیم. بیایید محدوده بازه را با فرمول تعیین کنیم:
![]()
که در آن X max حداکثر مقدار ویژگی گروه بندی است. Xmin حداقل مقدار ویژگی گروه بندی است. n تعداد فواصل است:
ما n=5 را می پذیریم. مرحله این است: h \u003d (192 - 159) / 5 \u003d 6.6
بیایید یک گروه بندی فاصله ای ایجاد کنیم

برای محاسبات بیشتر، یک جدول کمکی می سازیم:

X "i - وسط فاصله. (به عنوان مثال، وسط فاصله 159 - 165.6 \u003d 162.3)
میانگین رشد دانش آموزان با فرمول میانگین موزون حسابی تعیین می شود:

ما پراکندگی را با فرمول تعیین می کنیم:
فرمول را می توان به صورت زیر تبدیل کرد:

از این فرمول نتیجه می شود که واریانس است تفاوت بین میانگین مربع های گزینه ها و مربع و میانگین.
واریانس در سری تغییراتبا فواصل مساوی با توجه به روش گشتاورها را می توان به روش زیر با استفاده از خاصیت پراکندگی دوم (تقسیم همه گزینه ها بر مقدار بازه) محاسبه کرد. تعریف واریانسمحاسبه شده به روش ممان، طبق فرمول زیر زمان کمتری دارد:

جایی که i مقدار بازه است. الف - صفر مشروط، که برای استفاده از وسط بازه با بالاترین فرکانس راحت است. m1 مربع ممان مرتبه اول است. m2 - لحظه سفارش دوم
واریانس ویژگی (اگر در جامعه آماری ویژگی به گونه ای تغییر کند که تنها دو گزینه متقابل وجود داشته باشد، آنگاه چنین متغیری جایگزین نامیده می شود) را می توان با فرمول محاسبه کرد:

با جایگزینی در این فرمول پراکندگی q = 1- p، به دست می آوریم:

انواع پراکندگی
واریانس کلتغییرات یک صفت را در کل جمعیت به عنوان یک کل تحت تأثیر همه عواملی که باعث این تنوع می شوند اندازه گیری می کند. این برابر است با میانگین مربع انحراف مقادیر فردی ویژگی x از مقدار متوسط کل x و می تواند به عنوان واریانس ساده یا واریانس وزنی تعریف شود.
واریانس درون گروهی تغییرات تصادفی را مشخص می کند، یعنی. بخشی از تغییرات، که به دلیل تأثیر عوامل نامشخص است و به عامل علامت زیربنای گروه بندی بستگی ندارد. این واریانس برابر است با میانگین مجذور انحراف مقادیر فردی صفت در گروه X از میانگین حسابی گروه و می تواند به عنوان یک واریانس ساده یا به عنوان واریانس وزنی محاسبه شود.
به این ترتیب، اندازه گیری های واریانس درون گروهیتنوع یک صفت در یک گروه و با فرمول تعیین می شود:

جایی که xi - میانگین گروه. ni تعداد واحدهای گروه است.
به عنوان مثال، واریانسهای درون گروهی که باید در کار مطالعه تأثیر صلاحیتهای کارگران بر سطح بهرهوری نیروی کار در یک کارگاه تعیین شوند، تغییرات در تولید را در هر گروه نشان میدهند که ناشی از همه عوامل ممکن است (وضعیت فنی تجهیزات، در دسترس بودن ابزار و مواد، سن کارگران، شدت کار و...) به جز تفاوت در رده صلاحیت (در گروه، همه کارگران دارای صلاحیت یکسان هستند).
میانگین واریانس های درون گروهی منعکس کننده تغییرات تصادفی است، یعنی بخشی از تغییرات که تحت تأثیر همه عوامل دیگر به استثنای عامل گروه بندی رخ داده است. با فرمول محاسبه می شود:

واریانس بین گروهیتنوع سیستماتیک صفت حاصل را مشخص می کند که به دلیل تأثیر عامل صفت زیربنایی گروه بندی است. برابر است با مجذور میانگین انحراف میانگین های گروه از میانگین کلی. واریانس بین گروهی با فرمول محاسبه می شود: