1 واریانس را تعیین کنید. پراکندگی و انحراف معیار
ما محاسبه می کنیمخانمبرتری داشتنواریانس و انحراف معیار نمونه. ما همچنین واریانس یک متغیر تصادفی را در صورتی که توزیع آن مشخص باشد محاسبه می کنیم.
ابتدا در نظر بگیرید واریانس، سپس انحراف معیار.
واریانس نمونه
واریانس نمونه (واریانس نمونه،نمونهواریانس) گسترش مقادیر در آرایه را نسبت به.
هر 3 فرمول از نظر ریاضی معادل هستند.
از فرمول اول مشاهده می شود که واریانس نمونهمجموع مجذور انحرافات هر مقدار در آرایه است از متوسطتقسیم بر حجم نمونه منهای 1.
واریانس نمونه برداریتابع DISP () استفاده می شود. نام VAR، یعنی واریانس از آنجایی که نسخه MS EXCEL 2010 توصیه می شود از آنالوگ DISP.B ()، eng. نام VARS، یعنی. واریانس نمونه علاوه بر این، از نسخه MS EXCEL 2010 یک تابع انگلیسی DISP.G () وجود دارد. نام VARP، یعنی VARiance جمعیت، که محاسبه می کند واریانسبرای جمعیت عمومی... همه تفاوت ها به مخرج می رسد: به جای n-1 مانند DISP.V ()، در DISP.G ()، مخرج فقط n است. قبل از MS EXCEL 2010، تابع VARP () برای محاسبه واریانس جمعیت عمومی استفاده می شد.
واریانس نمونه
= مربع (نمونه) / (COUNT (نمونه) -1)
= (SUM (نمونه) -COUNT (نمونه) * AVERAGE (نمونه) ^ 2) / (COUNT (نمونه) -1)- فرمول معمول
= SUM ((نمونه -VALUE (نمونه)) ^ 2) / (COUNT (نمونه) -1) –
واریانس نمونهبرابر 0 است، تنها در صورتی که همه مقادیر با یکدیگر برابر باشند و بر این اساس، برابر باشند میانگین... معمولاً هر چه مقدار آن بزرگتر باشد واریانس، گسترش مقادیر در آرایه بیشتر است.
واریانس نمونهیک تخمین نقطه ای است واریانستوزیع متغیر تصادفی که از آن نمونه... در مورد ساختمان فاصله اطمیناندر ارزیابی واریانسرا می توان در مقاله خواند.
واریانس یک متغیر تصادفی
برای محاسبه واریانسمتغیر تصادفی، شما باید آن را بدانید.
برای واریانسمتغیر تصادفی X اغلب از نماد Var (X) استفاده می شود. پراکندگیبرابر مربع انحراف از میانگین E (X): Var (X) = E [(X-E (X)) 2]
پراکندگیبا فرمول محاسبه می شود:

که در آن x i مقداری است که متغیر تصادفی می تواند بگیرد، و μ مقدار متوسط ()، p (x) احتمال این است که متغیر تصادفی مقدار x را بگیرد.
اگر متغیر تصادفی داشته باشد، پس پراکندگیبا فرمول محاسبه می شود:

بعد، ابعاد، اندازه واریانسبا مربع واحد اندازه گیری مقادیر اصلی مطابقت دارد. به عنوان مثال، اگر مقادیر موجود در نمونه اندازه گیری وزن قطعه (به کیلوگرم) باشد، بعد واریانس کیلوگرم 2 خواهد بود. تفسیر این می تواند دشوار باشد، بنابراین، برای توصیف گسترش ارزش ها، مقداری برابر با ریشه دوم واریانس – انحراف معیار.
برخی از خواص واریانس:
Var (X + a) = Var (X)، که در آن X یک متغیر تصادفی و a یک ثابت است.
Var (aX) = a 2 Var (X)
Var (X) = E [(XE (X)) 2] = E = E (X 2) -E (2 * X * E (X)) + (E (X)) 2 = E (X 2) - 2 * E (X) * E (X) + (E (X)) 2 = E (X 2) - (E (X)) 2
این ویژگی واریانس در مقاله در مورد رگرسیون خطی.
Var (X + Y) = Var (X) + Var (Y) + 2 * Cov (X; Y)، که در آن X و Y متغیرهای تصادفی هستند، Cov (X; Y) کوواریانس این متغیرهای تصادفی است.
اگر متغیرهای تصادفی مستقل باشند، آنها کوواریانسبرابر 0 است، و بنابراین، Var (X + Y) = Var (X) + Var (Y). این ویژگی واریانس در خروجی استفاده می شود.
اجازه دهید نشان دهیم که برای مقادیر مستقل Var (X-Y) = Var (X + Y). در واقع، Var (X-Y) = Var (X-Y) = Var (X + (- Y)) = Var (X) + Var (-Y) = Var (X) + Var (-Y) = Var (X) + ( - 1) 2 Var (Y) = Var (X) + Var (Y) = Var (X + Y). این ویژگی واریانس برای رسم استفاده می شود.
انحراف استاندارد نمونه
انحراف استاندارد نمونهاندازه گیری میزان پراکندگی مقادیر موجود در نمونه نسبت به مقادیر آنها است.
الف مقدماتی، انحراف معیاربرابر با جذر واریانس:

انحراف معیاربزرگی مقادیر موجود در آن را در نظر نمی گیرد نمونه، اما فقط درجه پراکندگی مقادیر در اطراف آنها وسط... در اینجا یک مثال برای نشان دادن این موضوع آورده شده است.
بیایید انحراف معیار را برای 2 نمونه محاسبه کنیم: (1؛ 5؛ 9) و (1001؛ 1005؛ 1009). در هر دو مورد، s = 4. بدیهی است که نسبت انحراف استاندارد به مقادیر آرایه برای نمونه ها به طور قابل توجهی متفاوت است. برای چنین مواردی استفاده کنید ضریب تغییرات(ضریب تغییرات، CV) - نسبت انحراف معیارتا وسط حسابیبه صورت درصد بیان می شود.
در MS EXCEL 2007 و قبل از آن، برای محاسبه انحراف استاندارد نمونهتابع استفاده می شود = STDEV ()، eng. نام STDEV، یعنی. انحراف معیار. از آنجایی که نسخه MS EXCEL 2010 توصیه می شود از آنالوگ آن = STDEV.V () استفاده کنید. نام STDEV.S، یعنی. نمونه انحراف استاندارد.
علاوه بر این، با شروع از نسخه MS EXCEL 2010، یک تابع STDEV.G ()، eng. نام STDEV.P، یعنی. انحراف استاندارد جمعیت، که محاسبه می کند انحراف معیاربرای جمعیت عمومی... کل تفاوت به مخرج مربوط می شود: به جای n-1 مانند STDEV.V ()، STDEV.G () فقط n در مخرج دارد.
انحراف معیارهمچنین می توان مستقیماً با فرمول های زیر محاسبه کرد (به فایل نمونه مراجعه کنید)
= ROOT (SQUARE (نمونه) / (COUNT (نمونه) -1))
= ROOT ((SUM (نمونه) -COUNT (نمونه) * AVERAGE (نمونه) ^ 2) / (COUNT (نمونه) -1))
سایر اقدامات گسترش
تابع SQUARE () با محاسبه می شود اما مجذور انحراف مقادیر از آنها وسط... این تابع همان نتیجه را با فرمول = DISP.G ( نمونه)*بررسی( نمونه) ، جایی که نمونه- ارجاع به محدوده ای حاوی آرایه ای از مقادیر نمونه (). محاسبات در تابع SQUARE () طبق فرمول انجام می شود:

تابع AVEDEV () همچنین معیاری برای اندازه گیری گسترش مجموعه ای از داده ها است. تابع AVEDEV () میانگین مقادیر مطلق انحراف مقادیر را محاسبه می کند وسط... این تابع همان نتیجه فرمول را برمی گرداند = SUMPRODUCT (ABS (نمونه-متوسط (نمونه))) / COUNT (نمونه)، جایی که نمونه- ارجاع به یک محدوده حاوی آرایه ای از مقادیر نمونه.
محاسبات در تابع AVEDV () طبق فرمول انجام می شود:

انتظارات و واریانس ریاضی رایج ترین مشخصه های عددی متغیر تصادفی هستند. آنها مهمترین ویژگی های توزیع را مشخص می کنند: موقعیت آن و درجه پراکندگی. در بسیاری از مسائل عملی، یک مشخصه کامل و جامع یک متغیر تصادفی - قانون توزیع - یا اصلاً به دست نمی آید یا اصلاً مورد نیاز نیست. در این موارد، آنها به توصیف تقریبی یک متغیر تصادفی با استفاده از ویژگیهای عددی محدود میشوند.
انتظارات ریاضی اغلب صرفاً به عنوان میانگین یک متغیر تصادفی نامیده می شود. پراکندگی یک متغیر تصادفی مشخصه پراکندگی است، پراکندگی یک متغیر تصادفی در مورد انتظارات ریاضی آن.
انتظارات ریاضی از یک متغیر تصادفی گسسته
بیایید به مفهوم انتظار ریاضی نزدیک شویم، ابتدا از یک تفسیر مکانیکی از توزیع یک متغیر تصادفی گسسته استفاده کنیم. بگذارید واحد جرم بین نقاط محور آبسیسا توزیع شود ایکس1 , ایکس 2 , ..., ایکس n، و هر نقطه مادی دارای جرم مربوطه از پ1 , پ 2 , ..., پ n... لازم است یک نقطه در محور آبسیسا انتخاب شود که موقعیت کل سیستم نقاط مادی را با در نظر گرفتن جرم آنها مشخص می کند. طبیعی است که مرکز جرم سیستم نقاط مادی را چنین نقطه ای در نظر بگیریم. این میانگین وزنی یک متغیر تصادفی است ایکس، که در آن آبسیسه هر نقطه ایکسمنبا "وزن" برابر با احتمال مربوطه وارد می شود. مقدار میانگین متغیر تصادفی از این طریق به دست می آید ایکسانتظار ریاضی آن نامیده می شود.
انتظارات ریاضی از یک متغیر تصادفی گسسته، مجموع حاصل از همه مقادیر ممکن آن با احتمالات این مقادیر است:
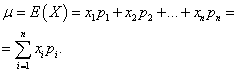
مثال 1.قرعه کشی برد-برد برگزار شد. 1000 برد وجود دارد که 400 مورد آن 10 روبل است. هر کدام 300 - 20 روبل 200 - 100 روبل. و هر کدام 100 - 200 روبل. میانگین برد برای یک خریدار بلیط چقدر است؟
راه حل. اگر مجموع بردها که 10 * 400 + 20 * 300 + 100 * 200 + 200 * 100 = 50000 روبل است، بر 1000 تقسیم شود (مجموع برد) میانگین برد را خواهیم یافت. سپس 50000/1000 = 50 روبل می گیریم. اما عبارت محاسبه میانگین سود را می توان به شکل زیر ارائه کرد:
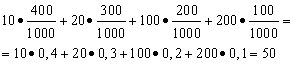
از طرف دیگر، در این شرایط، مقدار برد یک متغیر تصادفی است که می تواند مقادیر 10، 20، 100 و 200 روبل را به خود اختصاص دهد. با احتمالات برابر با 0.4، به ترتیب؛ 0.3; 0.2; 0.1. در نتیجه، میانگین سود مورد انتظار برابر است با مجموع محصولات بردها و احتمال دریافت آنها.
مثال 2.ناشر تصمیم گرفت کتاب جدیدی منتشر کند. او قصد دارد کتاب را به قیمت 280 روبل بفروشد که 200 روبل، 50 - کتابفروشی و 30 - نویسنده دریافت می کند. این جدول اطلاعاتی در مورد هزینه چاپ یک کتاب و احتمال فروش تعداد معینی از نسخه از کتاب ارائه می دهد.
سود مورد انتظار ناشر را بیابید.
راه حل. مقدار تصادفی "سود" برابر است با تفاوت بین درآمد حاصل از فروش و بهای تمام شده هزینه ها. به عنوان مثال، اگر 500 نسخه از یک کتاب فروخته شود، درآمد حاصل از فروش 200 * 500 = 100000 و هزینه چاپ 225000 روبل است. بنابراین، ناشر با ضرر 125000 روبلی مواجه است. جدول زیر مقادیر مورد انتظار متغیر تصادفی - سود را خلاصه می کند:
| عدد | سود ایکسمن | احتمال پمن | ایکسمن پمن |
| 500 | -125000 | 0,20 | -25000 |
| 1000 | -50000 | 0,40 | -20000 |
| 2000 | 100000 | 0,25 | 25000 |
| 3000 | 250000 | 0,10 | 25000 |
| 4000 | 400000 | 0,05 | 20000 |
| جمع: | 1,00 | 25000 |
بنابراین، ما انتظار ریاضی سود ناشر را دریافت می کنیم:
![]() .
.
مثال 3.احتمال ضربه در هر شات پ= 0.2. میزان مصرف پرتابه ها را تعیین کنید که یک انتظار ریاضی از تعداد ضربه ها برابر با 5 است.
راه حل. از همان فرمول انتظار ریاضی که تا کنون استفاده کرده ایم بیان می کنیم ایکس- مصرف پرتابه:
![]() .
.
مثال 4.انتظارات ریاضی از یک متغیر تصادفی را تعیین کنید ایکستعداد ضربه ها برای سه ضربه، در صورتی که احتمال ضربه برای هر شلیک وجود داشته باشد پ = 0,4 .
نکته: احتمال مقادیر یک متغیر تصادفی توسط فرمول برنولی .
ویژگی های انتظارات ریاضی
ویژگی های انتظار ریاضی را در نظر بگیرید.
ملک 1.انتظار ریاضی از یک ثابت برابر است با این ثابت:
ملک 2.عامل ثابت را می توان از علامت انتظار ریاضی خارج کرد:
![]()
ملک 3.انتظار ریاضی از مجموع (تفاوت) متغیرهای تصادفی برابر است با مجموع (تفاوت) انتظارات ریاضی آنها:
ملک 4.انتظارات ریاضی حاصل ضرب متغیرهای تصادفی برابر است با حاصل ضرب انتظارات ریاضی آنها:
ملک 5.اگر تمام مقادیر متغیر تصادفی ایکسکاهش (افزایش) به همان تعداد با، سپس انتظار ریاضی آن به همان مقدار کاهش می یابد (افزایش می یابد):
![]()
زمانی که نمی توان تنها با انتظارات ریاضی محدود شد
در بیشتر موارد، انتظارات ریاضی به تنهایی نمی تواند به اندازه کافی متغیر تصادفی را مشخص کند.
اجازه دهید متغیرهای تصادفی ایکسو Yتوسط قوانین توزیع زیر ارائه می شود:
| معنی ایکس | احتمال |
| -0,1 | 0,1 |
| -0,01 | 0,2 |
| 0 | 0,4 |
| 0,01 | 0,2 |
| 0,1 | 0,1 |
| معنی Y | احتمال |
| -20 | 0,3 |
| -10 | 0,1 |
| 0 | 0,2 |
| 10 | 0,1 |
| 20 | 0,3 |
انتظارات ریاضی از این مقادیر یکسان است - برابر با صفر:
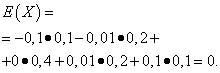
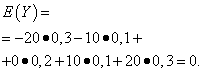
با این حال، ماهیت توزیع آنها متفاوت است. مقدار تصادفی ایکسمی تواند فقط مقادیری را بگیرد که کمی با انتظارات ریاضی و متغیر تصادفی متفاوت است Yمی تواند مقادیری را به دست آورد که به طور قابل توجهی از انتظارات ریاضی انحراف دارد. مثال مشابه: دستمزد متوسط قضاوت در مورد نسبت کارگران با دستمزد بالا و پایین را غیرممکن می کند. به عبارت دیگر، نمی توان با انتظارات ریاضی قضاوت کرد که چه انحرافی از آن، حداقل به طور متوسط، ممکن است. برای این کار باید واریانس متغیر تصادفی را پیدا کنید.
پراکندگی یک متغیر تصادفی گسسته
پراکندگیمتغیر تصادفی گسسته ایکسانتظار ریاضی مربع انحراف آن از انتظار ریاضی است:
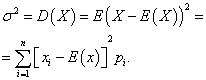
انحراف معیار یک متغیر تصادفی ایکسمقدار حسابی جذر واریانس آن را می گویند:
![]() .
.
مثال 5.محاسبه واریانس و انحراف معیار متغیرهای تصادفی ایکسو Yکه قوانین توزیع آن در جداول بالا آورده شده است.
راه حل. انتظارات ریاضی از متغیرهای تصادفی ایکسو Y، همانطور که در بالا مشاهده شد، برابر با صفر هستند. با توجه به فرمول پراکندگی در E(NS)=E(y) = 0 دریافت می کنیم:

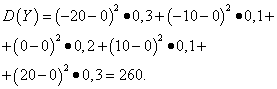
سپس انحراف معیار متغیرهای تصادفی ایکسو Yآرایش
![]() .
.
بنابراین، با همان انتظارات ریاضی، واریانس متغیر تصادفی ایکسبسیار کوچک است، اما یک متغیر تصادفی است Y- قابل توجه. این نتیجه تفاوت در توزیع آنهاست.
مثال 6.سرمایه گذار دارای 4 پروژه سرمایه گذاری جایگزین است. جدول سود مورد انتظار در این پروژه ها را با احتمال مربوطه خلاصه می کند.
| پروژه 1 | پروژه 2 | پروژه 3 | پروژه 4 |
| 500, پ=1 | 1000, پ=0,5 | 500, پ=0,5 | 500, پ=0,5 |
| 0, پ=0,5 | 1000, پ=0,25 | 10500, پ=0,25 | |
| 0, پ=0,25 | 9500, پ=0,25 |
انتظارات ریاضی، واریانس و انحراف معیار را برای هر جایگزین بیابید.
راه حل. بیایید نشان دهیم که چگونه این مقادیر برای جایگزین 3 محاسبه می شود:
جدول مقادیر یافت شده برای همه گزینه ها را خلاصه می کند.
همه جایگزین ها انتظارات ریاضی یکسانی دارند. این بدان معناست که در درازمدت، درآمد همه یکسان است. انحراف استاندارد را می توان به عنوان واحد اندازه گیری ریسک تفسیر کرد - هر چه بزرگتر باشد، ریسک سرمایه گذاری بیشتر می شود. سرمایهگذاری که ریسک زیادی نمیخواهد، پروژه 1 را انتخاب میکند، زیرا دارای کمترین انحراف استاندارد (0) است. اگر سرمایه گذار در مدت کوتاهی به ریسک و بازدهی زیاد اولویت بدهد، پروژه را با بیشترین انحراف معیار - پروژه 4 انتخاب می کند.
خواص پراکندگی
در اینجا ویژگی های واریانس آورده شده است.
ملک 1.واریانس ثابت صفر است:
ملک 2.ضریب ثابت را می توان با مجذور کردن آن از علامت واریانس خارج کرد:
![]() .
.
ملک 3.واریانس یک متغیر تصادفی برابر است با انتظار ریاضی مربع این کمیت که مجذور انتظار ریاضی خود کمیت از آن کم می شود:
![]() ,
,
جایی که ![]() .
.
ملک 4.واریانس مجموع (تفاوت) متغیرهای تصادفی برابر است با مجموع (تفاوت) واریانس آنها:
مثال 7.مشخص است که یک متغیر تصادفی گسسته ایکسفقط دو مقدار را می گیرد: -3 و 7. علاوه بر این، انتظارات ریاضی مشخص است: E(ایکس) = 4. واریانس یک متغیر تصادفی گسسته را پیدا کنید.
راه حل. اجازه دهید با نشان دادن پاحتمالی که یک متغیر تصادفی یک مقدار می گیرد ایکس1 = −3 ... سپس احتمال مقدار ایکس2 = 7 1 خواهد بود - پ... اجازه دهید معادله انتظار ریاضی را استخراج کنیم:
E(ایکس) = ایکس 1 پ + ایکس 2 (1 − پ) = −3پ + 7(1 − پ) = 4 ,
از آنجا احتمالات را بدست می آوریم: پ= 0.3 و 1 - پ = 0,7 .
قانون توزیع یک متغیر تصادفی:
| ایکس | −3 | 7 |
| پ | 0,3 | 0,7 |
ما واریانس این متغیر تصادفی را با فرمول از ویژگی 3 واریانس محاسبه می کنیم:
دی(ایکس) = 2,7 + 34,3 − 16 = 21 .
انتظارات ریاضی یک متغیر تصادفی را خودتان پیدا کنید و سپس به راه حل نگاه کنید
مثال 8.متغیر تصادفی گسسته ایکسفقط دو مقدار می گیرد. بزرگتر از مقادیر 3 را با احتمال 0.4 می پذیرد. علاوه بر این، واریانس متغیر تصادفی مشخص است دی(ایکس) = 6. انتظارات ریاضی یک متغیر تصادفی را پیدا کنید.
مثال 9. 6 توپ سفید و 4 توپ سیاه در کوزه وجود دارد. 3 توپ از کوزه خارج می شود. تعداد توپهای سفید در میان توپهایی که بیرون آورده میشوند یک متغیر تصادفی گسسته است ایکس... انتظارات ریاضی و واریانس این متغیر تصادفی را بیابید.
راه حل. مقدار تصادفی ایکسمی تواند مقادیر 0، 1، 2، 3 را بگیرد. احتمالات مربوطه را می توان از قانون ضرب احتمالات... قانون توزیع یک متغیر تصادفی:
| ایکس | 0 | 1 | 2 | 3 |
| پ | 1/30 | 3/10 | 1/2 | 1/6 |
بنابراین انتظارات ریاضی از یک متغیر تصادفی معین:
م(ایکس) = 3/10 + 1 + 1/2 = 1,8 .
واریانس یک متغیر تصادفی داده شده:
دی(ایکس) = 0,3 + 2 + 1,5 − 3,24 = 0,56 .
انتظارات ریاضی و واریانس یک متغیر تصادفی پیوسته
برای یک متغیر تصادفی پیوسته، تفسیر مکانیکی انتظار ریاضی همان معنی را حفظ خواهد کرد: مرکز جرم برای یک واحد جرم، که به طور پیوسته بر روی محور آبسیسا با چگالی توزیع شده است. f(ایکس). در مقابل یک متغیر تصادفی گسسته، که در آن آرگومان تابع ایکسمنبه طور ناگهانی تغییر می کند، برای یک متغیر تصادفی پیوسته، آرگومان به طور مداوم تغییر می کند. اما انتظارات ریاضی از یک متغیر تصادفی پیوسته با مقدار میانگین آن نیز مرتبط است.
برای یافتن انتظارات ریاضی و واریانس یک متغیر تصادفی پیوسته، باید انتگرال های خاصی را پیدا کنید. ... اگر تابع چگالی یک متغیر تصادفی پیوسته داده شود، آنگاه مستقیماً وارد انتگرال می شود. اگر یک تابع توزیع احتمال داده شود، پس با تفکیک آن، باید تابع چگالی را پیدا کنید.
میانگین حسابی همه مقادیر ممکن یک متغیر تصادفی پیوسته آن نامیده می شود انتظارات ریاضی، با یا نشان داده می شود.
نظریه احتمال شاخه خاصی از ریاضیات است که فقط توسط دانشجویان دانشگاه مورد مطالعه قرار می گیرد. آیا محاسبات و فرمول ها را دوست دارید؟ آیا از چشم انداز آشنایی با توزیع نرمال، آنتروپی مجموعه، انتظارات ریاضی و واریانس یک متغیر تصادفی گسسته نمی ترسید؟ سپس این موضوع برای شما بسیار جالب خواهد بود. بیایید با برخی از مهمترین مفاهیم پایه در این شاخه از علم آشنا شویم.
بیایید اصول اولیه را به خاطر بسپاریم
حتی اگر ساده ترین مفاهیم نظریه احتمال را به خاطر دارید، از پاراگراف های اول مقاله غافل نشوید. واقعیت این است که بدون درک روشنی از اصول اولیه، نمی توانید با فرمول های مورد بحث در زیر کار کنید.
بنابراین، یک رویداد تصادفی رخ می دهد، یک آزمایش. در نتیجه اقدامات انجام شده، می توانیم چندین نتیجه را به دست آوریم - برخی از آنها رایج تر هستند، برخی دیگر کمتر رایج هستند. احتمال یک رویداد نسبت تعداد نتایج واقعی به دست آمده از یک نوع به تعداد کل نتایج ممکن است. تنها با دانستن تعریف کلاسیک این مفهوم، می توانید مطالعه انتظارات ریاضی و واریانس متغیرهای تصادفی پیوسته را شروع کنید.
میانگین
در مدرسه، در درس ریاضی، کار را با میانگین حسابی شروع کردید. این مفهوم به طور گسترده در نظریه احتمال استفاده می شود و بنابراین نمی توان آن را نادیده گرفت. نکته اصلی برای ما در حال حاضر این است که در فرمول های انتظار ریاضی و واریانس یک متغیر تصادفی با آن مواجه خواهیم شد.

ما دنباله ای از اعداد داریم و می خواهیم میانگین حسابی را پیدا کنیم. تنها چیزی که از ما لازم است این است که همه چیزهای موجود را جمع کنیم و بر تعداد عناصر در دنباله تقسیم کنیم. فرض کنید اعدادی از 1 تا 9 داریم. مجموع عناصر 45 می شود و این مقدار را بر 9 تقسیم می کنیم. پاسخ: - 5.
پراکندگی
در اصطلاح علمی، واریانس میانگین مجذور انحراف مقادیر به دست آمده یک ویژگی از میانگین حسابی است. یکی با حرف بزرگ لاتین D نشان داده می شود. برای محاسبه آن به چه چیزی نیاز دارید؟ برای هر عنصر دنباله، تفاوت بین عدد موجود و میانگین حسابی را محاسبه کرده و آن را مربع کنید. برای رویدادی که در نظر می گیریم دقیقاً به همان اندازه ارزش وجود خواهد داشت. در مرحله بعد، همه دریافتها را خلاصه میکنیم و بر تعداد عناصر موجود در دنباله تقسیم میکنیم. اگر پنج نتیجه ممکن داشته باشیم، بر پنج تقسیم می کنیم.

واریانس همچنین دارای ویژگی هایی است که برای اعمال در هنگام حل مسائل باید به خاطر بسپارید. به عنوان مثال، هنگامی که یک متغیر تصادفی X برابر افزایش می یابد، واریانس به X برابر مربع افزایش می یابد (یعنی X * X). هرگز کمتر از صفر نیست و به جابجایی مقادیر با یک مقدار مساوی به بالا یا پایین بستگی ندارد. علاوه بر این، برای آزمون های مستقل، واریانس مجموع برابر با مجموع واریانس ها است.
اکنون قطعاً باید نمونه هایی از واریانس یک متغیر تصادفی گسسته و انتظارات ریاضی را در نظر بگیریم.
فرض کنید 21 آزمایش انجام دادیم و 7 نتیجه متفاوت گرفتیم. هر کدام را به ترتیب 1،2،2،3،4،4 و 5 بار مشاهده کردیم. واریانس چیست؟
اول، بیایید میانگین حسابی را محاسبه کنیم: مجموع عناصر، البته، برابر با 21 است. آن را بر 7 تقسیم کنید و عدد 3 را به دست آورید. حالا از هر عدد در دنباله اصلی، 3 را کم کنید، هر مقدار را مربع کنید و عدد را اضافه کنید. نتایج با هم معلوم می شود 12. اکنون فقط باید عدد را بر تعداد عناصر تقسیم کنیم، و به نظر می رسد، همین است. اما یک گرفتاری وجود دارد! بیایید در مورد آن بحث کنیم.
وابستگی به تعداد آزمایش
معلوم می شود که هنگام محاسبه واریانس، مخرج می تواند یکی از دو عدد باشد: N یا N-1. در اینجا N تعداد آزمایش های انجام شده یا تعداد آیتم های دنباله (که اساساً یکسان هستند) است. به چه چیزی بستگی دارد؟

اگر تعداد تستها به صدها اندازهگیری شود، باید مخرج N را وارد کنیم. اگر به واحد است، N-1. دانشمندان تصمیم گرفتند مرز را کاملاً نمادین ترسیم کنند: امروز روی عدد 30 قرار دارد. اگر کمتر از 30 آزمایش انجام داده باشیم، مجموع را بر N-1 و اگر بیشتر باشد، بر N تقسیم می کنیم.
وظیفه
بیایید به مثال خود در مورد حل مسئله واریانس و انتظار برگردیم. ما یک عدد متوسط 12 گرفتیم که باید بر N یا N-1 تقسیم می شد. از آنجایی که ما 21 آزمایش انجام دادیم که کمتر از 30 آزمایش است، گزینه دوم را انتخاب می کنیم. بنابراین پاسخ این است: واریانس 12/2 = 2 است.
ارزش مورد انتظار
بریم سراغ مفهوم دوم که حتما در این مقاله باید به آن توجه کنیم. مقدار مورد انتظار مجموع تمام نتایج ممکن ضرب در احتمالات مربوطه است. درک این نکته مهم است که مقدار به دست آمده و همچنین نتیجه محاسبه واریانس، صرف نظر از اینکه چند نتیجه در آن در نظر گرفته می شود، تنها یک بار برای کل مسئله به دست می آید.

فرمول انتظارات ریاضی بسیار ساده است: ما نتیجه را می گیریم، در احتمال آن ضرب می کنیم، همان را برای نتیجه دوم، سوم و غیره اضافه می کنیم. همه چیز مربوط به این مفهوم به راحتی قابل محاسبه است. به عنوان مثال، مجموع انتظار برابر است با انتظار از مجموع. در مورد یک اثر هم همینطور است. هر مقدار در تئوری احتمال اجازه نمی دهد که چنین عملیات ساده ای با خودش انجام شود. بیایید یک مسئله را در نظر بگیریم و معنای دو مفهومی را که به طور همزمان مطالعه کردیم محاسبه کنیم. علاوه بر این، تئوری حواسمان را پرت کرد - وقت آن است که تمرین کنیم.
یک مثال دیگر
ما 50 کارآزمایی انجام دادیم و 10 نوع نتیجه گرفتیم - اعداد از 0 تا 9 - که در درصدهای مختلف اتفاق میافتند. اینها به ترتیب عبارتند از: 2٪، 10٪، 4٪، 14٪، 2٪، 18٪، 6٪، 16٪، 10٪، 18٪. به یاد بیاورید که برای به دست آوردن احتمالات، باید مقادیر را بر حسب درصد بر 100 تقسیم کنید. بنابراین، 0.02 به دست می آید. 0.1 و غیره اجازه دهید مثالی از حل مسئله برای واریانس یک متغیر تصادفی و انتظار ریاضی ارائه کنیم.
میانگین حسابی را با استفاده از فرمولی که از دبستان به خاطر داریم محاسبه می کنیم: 50/10 = 5.
حالا بیایید احتمالات را به تعداد پیامدهای «تکهای» تبدیل کنیم تا شمارش آسانتر شود. 1، 5، 2، 7، 1، 9، 3، 8، 5 و 9 را به دست می آوریم. از هر مقدار به دست آمده، میانگین حسابی را کم می کنیم، پس از آن هر یک از نتایج به دست آمده را مربع می کنیم. نحوه انجام این کار را با استفاده از عنصر اول به عنوان مثال ببینید: 1 - 5 = (-4). بعد: (-4) * (-4) = 16. برای بقیه مقادیر، این عملیات را خودتان انجام دهید. اگر همه چیز را به درستی انجام دادید، پس از اضافه کردن همه، 90 دریافت خواهید کرد.

بیایید محاسبه واریانس و میانگین را با تقسیم 90 بر N ادامه دهیم. چرا N را انتخاب می کنیم و N-1 را انتخاب نمی کنیم؟ درست است، زیرا تعداد آزمایش های انجام شده بیش از 30 است. بنابراین: 90/10 = 9. ما واریانس را دریافت کردیم. اگر شماره دیگری دریافت کردید، ناامید نشوید. به احتمال زیاد، شما یک اشتباه رایج در محاسبات مرتکب شده اید. آنچه نوشته اید را دوباره بررسی کنید، مطمئن باشید همه چیز سر جای خود قرار می گیرد.
در نهایت، بیایید فرمول انتظارات ریاضی را یادآوری کنیم. ما تمام محاسبات را نمی دهیم، فقط پاسخی را می نویسیم که می توانید پس از انجام تمام مراحل مورد نیاز بررسی کنید. انتظار 5.48 خواهد بود. بگذارید فقط نحوه انجام عملیات را با استفاده از مثال عناصر اول به یاد بیاوریم: 0 * 0.02 + 1 * 0.1 ... و غیره. همانطور که می بینید، ما به سادگی مقدار نتیجه را در احتمال آن ضرب می کنیم.
انحراف
مفهوم دیگری که ارتباط نزدیکی با واریانس و انتظارات ریاضی دارد انحراف معیار است. یا با حروف لاتین sd یا با حروف کوچک یونانی "sigma" نشان داده می شود. این مفهوم نشان می دهد که مقادیر به طور متوسط چقدر از ویژگی مرکزی انحراف دارند. برای یافتن مقدار آن، باید جذر واریانس را محاسبه کنید.

اگر توزیع نرمال را رسم کنید و بخواهید انحراف مربع را مستقیماً روی آن ببینید، این کار را می توان در چند مرحله انجام داد. نیمی از تصویر را به سمت چپ یا راست حالت (مقدار مرکزی) بگیرید، یک عمود بر محور افقی بکشید تا مساحت اشکال به دست آمده برابر باشد. مقدار بخش بین وسط توزیع و برآمدگی حاصل بر روی محور افقی نشان دهنده انحراف معیار است.
نرم افزار
همانطور که از توضیحات فرمول ها و مثال های ارائه شده مشخص است، محاسبات واریانس و انتظارات ریاضی ساده ترین روش از نظر حسابی نیستند. برای اینکه زمان را هدر ندهید، استفاده از برنامه مورد استفاده در آموزش عالی منطقی است - آن را "R" می نامند. دارای توابعی است که به شما امکان می دهد مقادیر بسیاری از مفاهیم را از آمار و تئوری احتمال محاسبه کنید.
به عنوان مثال، شما در حال تعریف بردار مقادیر هستید. این کار به صورت زیر انجام می شود: برداری<-c(1,5,2…). Теперь, когда вам потребуется посчитать какие-либо значения для этого вектора, вы пишете функцию и задаете его в качестве аргумента. Для нахождения дисперсии вам нужно будет использовать функцию var. Пример её использования: var(vector). Далее вы просто нажимаете «ввод» и получаете результат.
سرانجام
پراکندگی و انتظارات ریاضی - بدون آن محاسبه هر چیزی در آینده دشوار است. در دوره اصلی سخنرانی در دانشگاه ها، آنها در ماه های اول مطالعه موضوع مورد توجه قرار می گیرند. به دلیل عدم درک این مفاهیم ساده و ناتوانی در محاسبه آنها است که بسیاری از دانش آموزان بلافاصله شروع به عقب افتادن از برنامه می کنند و بعداً بر اساس نتایج جلسه نمرات ضعیفی دریافت می کنند که آنها را از بورس تحصیلی محروم می کند.
حداقل یک هفته و نیم ساعت در روز تمرین کنید و کارهایی مشابه آنچه در این مقاله ارائه شده است را حل کنید. سپس در هر آزمونی در مورد تئوری احتمال، با مثال هایی بدون نکات اضافی و برگه های تقلب مقابله خواهید کرد.
با این حال، این ویژگی به تنهایی برای مطالعه یک متغیر تصادفی کافی نیست. تصور کنید دو تیرانداز به یک هدف شلیک می کنند. یکی با دقت شلیک می کند و نزدیک به مرکز ضربه می زند و دیگری ... فقط سرگرم می شود و حتی هدف نمی گیرد. اما آنچه خنده دار است مال اوست میانگیننتیجه دقیقاً مشابه تیرانداز اول خواهد بود! این وضعیت به طور معمول با متغیرهای تصادفی زیر نشان داده می شود:
انتظار ریاضی "تک تیرانداز" برای یک "شخصیت جالب" برابر است: - آن هم صفر است!
بنابراین، نیاز به تعیین کمیت تا کجا وجود دارد پراکنده شده استگلوله ها (مقادیر یک متغیر تصادفی) نسبت به مرکز هدف (انتظار ریاضی). خوب و پراکندگیاز لاتین فقط به عنوان ترجمه شده است پراکندگی .
بیایید ببینیم که چگونه این مشخصه عددی در یکی از مثال های قسمت اول درس تعیین می شود: 
در آنجا ما یک انتظار ریاضی ناامیدکننده از این بازی پیدا کردیم و اکنون باید واریانس آن را محاسبه کنیم که نشان داده شده استدر سراسر .
بیایید دریابیم که بردها / باخت ها نسبت به میانگین چقدر "پراکنده" هستند. بدیهی است که برای این کار باید محاسبه کنید تفاوتبین مقادیر یک متغیر تصادفیو او انتظارات ریاضی:
–5 – (–0,5) = –4,5
2,5 – (–0,5) = 3
10 – (–0,5) = 10,5
اکنون، به نظر می رسد، لازم است نتایج را خلاصه کنیم، اما این مسیر مناسب نیست - به این دلیل که نوسانات به سمت چپ با نوسانات به سمت راست خنثی می شوند. بنابراین، برای مثال، یک تیرانداز "آماتور". (مثال بالا)تفاوت این است ![]() ، و هنگامی که اضافه شود صفر می شود، بنابراین ما هیچ تخمینی از پراکندگی تیراندازی آن نخواهیم گرفت.
، و هنگامی که اضافه شود صفر می شود، بنابراین ما هیچ تخمینی از پراکندگی تیراندازی آن نخواهیم گرفت.
برای دور زدن این مزاحمت، می توانید در نظر بگیرید ماژول هاتفاوت ها، اما به دلایل فنی، این رویکرد زمانی ریشه دوانده است که آنها مربع شوند. ترسیم راه حل با جدول راحت تر است: 
و در اینجا التماس برای محاسبه است میانگین وزنیمقدار مربعات انحرافات چیست؟ مال آن هاست ارزش مورد انتظار، که معیار پراکندگی است:
![]() – تعریفواریانس بلافاصله از تعریف مشخص می شود که واریانس نمی تواند منفی باشد- برای تمرین توجه داشته باشید!
– تعریفواریانس بلافاصله از تعریف مشخص می شود که واریانس نمی تواند منفی باشد- برای تمرین توجه داشته باشید!
بیایید به یاد بیاوریم که چگونه انتظارات را پیدا کنیم. مجذور تفاوت ها را در احتمالات مربوطه ضرب می کنیم (ادامه جدول):
- به بیان مجازی، "نیروی کششی" است،
و نتایج را خلاصه کنید:
آیا فکر نمی کنید که در پس زمینه بردها، نتیجه خیلی بزرگ بود؟ درست است - ما مربع کردیم و برای بازگشت به بعد بازی خود، باید ریشه دوم را استخراج کنیم. این مقدار نامیده می شود انحراف معیار
و با حرف یونانی "سیگما" نشان داده می شود:
این مقدار گاهی اوقات نامیده می شود انحراف معیار .
معنی آن چیست؟ اگر با انحراف معیار از انتظارات ریاضی به چپ و راست منحرف شویم: ![]()
- سپس در این بازه، محتمل ترین مقادیر متغیر تصادفی "متمرکز" خواهد بود. آنچه در واقع مشاهده می کنیم:
با این حال، این اتفاق افتاد که هنگام تجزیه و تحلیل پراکندگی، تقریبا همیشه با مفهوم پراکندگی عمل می شود. بیایید ببینیم در رابطه با بازی ها چه معنایی دارد. اگر در مورد فلش ها در مورد "دقت" ضربه ها نسبت به مرکز هدف صحبت می کنیم، در اینجا واریانس دو چیز را مشخص می کند:
اولاً بدیهی است که با افزایش نرخ ها، واریانس نیز افزایش می یابد. بنابراین، برای مثال، اگر 10 برابر افزایش دهیم، انتظار ریاضی 10 برابر و واریانس 100 برابر خواهد شد. (تا زمانی که این مقدار درجه دوم باشد)... اما، توجه داشته باشید که قوانین بازی تغییر نکرده است! فقط نرخ ها تغییر کرده اند، به طور کلی، ما قبلاً 10 روبل شرط می کردیم، اکنون 100.
نکته دوم و جالب تر این است که واریانس سبک بازی را مشخص می کند. بیایید نرخ بازی را از نظر ذهنی اصلاح کنیم در یک سطح معینو ببینید اینجا چیست:
بازی کم واریانس یک بازی محتاطانه است. بازیکن تمایل دارد که قابل اعتمادترین طرح ها را انتخاب کند، جایی که او در یک زمان زیاد از دست نمی دهد / برنده می شود. به عنوان مثال، سیستم قرمز / سیاه در رولت (به مثال 4 مقاله مراجعه کنید متغیرهای تصادفی) .
بازی با واریانس بالا او اغلب نامیده می شود پراکندهبازی این یک سبک بازی ماجراجویانه یا تهاجمی است که در آن بازیکن طرح های افزایش آدرنالین را انتخاب می کند. حداقل یادمون باشه مارتینگل، که در آن مقادیری در خطر وجود دارد که مرتبه های بزرگی بالاتر از بازی "آرام" پاراگراف قبل هستند.
وضعیت در پوکر نشان دهنده است: به اصطلاح وجود دارد تنگبازیکنانی که تمایل دارند محتاط باشند و در مورد دارایی های بازی خود "ناراحتی" داشته باشند (با سرمایه گذاری)... جای تعجب نیست که سرمایه آنها نوسان زیادی ندارد (واریانس کم). برعکس، اگر بازیکنی واریانس بالایی داشته باشد، این مهاجم است. او اغلب ریسک میکند، شرطبندی بزرگ میکند و هم میتواند یک بانک بزرگ را بشکند و هم به فروشگاههای خرده فروشی برود.
همین اتفاق در فارکس و غیره رخ می دهد - نمونه های زیادی وجود دارد.
علاوه بر این، در همه موارد مهم نیست - آیا بازی برای یک پنی است یا برای هزاران دلار. هر سطحی بازیکنان با پراکندگی کم و زیاد خود را دارد. خوب، همانطور که به یاد داریم، بازده متوسط "مسئولیت" است ارزش مورد انتظار.
احتمالاً متوجه شده اید که یافتن واریانس فرآیندی طولانی و پر زحمت است. اما ریاضی سخاوتمندانه است:
فرمول یافتن واریانس
این فرمول مستقیماً از تعریف واریانس گرفته شده است و ما بلافاصله آن را در گردش قرار می دهیم. پلاک را با بازی خودمان از بالا کپی می کنم: 
و انتظار پیدا شده
بیایید واریانس را به روش دوم محاسبه کنیم. اول، انتظارات ریاضی را پیدا می کنیم - مربع یک متغیر تصادفی. توسط تعریف انتظار:
در این مورد:
بنابراین، طبق فرمول:
همانطور که می گویند تفاوت را احساس کنید. و البته در عمل بهتر است از فرمول استفاده شود (مگر اینکه شرط اقتضا کند).
ما بر تکنیک راه حل و طراحی مسلط هستیم:
مثال 6

انتظارات ریاضی، واریانس و انحراف معیار آن را بیابید.
این وظیفه در همه جا حاضر است و به عنوان یک قاعده، بدون معنی است.
می توانید چندین لامپ با اعداد را تصور کنید که در یک دیوانه خانه با احتمالات خاص روشن می شوند :)
راه حل: خلاصه کردن محاسبات اولیه در یک جدول راحت است. ابتدا داده های اصلی را در دو خط بالا می نویسیم. سپس محصولات را محاسبه می کنیم، سپس و در نهایت مجموع ستون سمت راست را محاسبه می کنیم: 
در واقع، تقریبا همه چیز آماده است. خط سوم شامل یک انتظار ریاضی آماده است: ![]() .
.
واریانس را با فرمول محاسبه می کنیم:
و در نهایت انحراف معیار:
- شخصاً معمولاً 2 رقم اعشار گرد می کنم.
تمام محاسبات را می توان در یک ماشین حساب یا حتی بهتر از آن در اکسل انجام داد:
اینجا اشتباه کردن سخته :)
پاسخ:
کسانی که مایلند می توانند زندگی خود را ساده تر کنند و از من استفاده کنند ماشین حساب (نسخه ی نمایشی)، که نه تنها این مشکل را فورا حل می کند، بلکه می سازد نمودارهای موضوعی (به زودی به آنجا خواهیم رسید)... برنامه می تواند دانلود در کتابخانه- اگر حداقل یک مطلب آموزشی دانلود کرده اید یا دریافت کرده اید یک راه دیگر... با تشکر از حمایت از پروژه!
چند کار برای یک راه حل مستقل:
مثال 7
واریانس متغیر تصادفی مثال قبلی را بر اساس تعریف محاسبه کنید.
و یک مثال مشابه:
مثال 8
یک متغیر تصادفی گسسته توسط قانون توزیع خودش داده می شود:

بله، مقادیر یک متغیر تصادفی می تواند بسیار بزرگ باشد (نمونه ای از کار واقعی)و در اینجا در صورت امکان از Excel استفاده کنید. همانطور که، اتفاقا، در مثال 7 - سریعتر، قابل اعتمادتر و لذت بخش تر است.
راه حل ها و پاسخ ها در پایین صفحه.
در پایان بخش دوم درس، یک مشکل معمولی دیگر را تجزیه و تحلیل خواهیم کرد، حتی می توان گفت یک ریبوس کوچک:
مثال 9
یک متغیر تصادفی گسسته می تواند تنها دو مقدار داشته باشد: و علاوه بر این. احتمال، انتظارات ریاضی و واریانس مشخص است.
راه حل: بیایید با یک احتمال مجهول شروع کنیم. از آنجایی که یک متغیر تصادفی می تواند تنها دو مقدار بگیرد، مجموع احتمالات رویدادهای مربوطه:
و از آن پس
باقی می ماند برای پیدا کردن ... آن را آسان به گفتن :) اما اوه خوب، ما می رویم. با تعریف انتظارات ریاضی: ![]() - مقادیر شناخته شده را جایگزین می کنیم:
- مقادیر شناخته شده را جایگزین می کنیم:
![]() - و هیچ چیز دیگری نمی توان از این معادله خارج کرد، به جز اینکه می توانید آن را در جهت معمول بازنویسی کنید:
- و هیچ چیز دیگری نمی توان از این معادله خارج کرد، به جز اینکه می توانید آن را در جهت معمول بازنویسی کنید: ![]()

یا: ![]()
در مورد اقدامات بعدی، فکر می کنم می توانید حدس بزنید. بیایید سیستم را بسازیم و حل کنیم: 
کسری اعشاری، البته، مایه شرمساری کامل است. هر دو معادله را در 10 ضرب کنید: 
و تقسیم بر 2: 
این خیلی بهتر است. از معادله 1 بیان می کنیم: ![]() (این یک راه ساده تر است)- در معادله 2 جایگزین می کنیم:
(این یک راه ساده تر است)- در معادله 2 جایگزین می کنیم:
![]()
ما می سازیم مربعو ساده سازی کنید: 
ضربدر: 
نتیجه این است معادله ی درجه دو، تمایز آن را پیدا می کنیم:
- کامل!
و دو راه حل می گیریم:
1) اگر ![]() ، سپس
، سپس ![]() ;
;
2) اگر ![]() ، سپس .
، سپس .
اولین جفت مقادیر شرط را برآورده می کند. با احتمال زیاد، همه چیز درست است، اما، با این وجود، قانون توزیع را می نویسیم: 
و ما بررسی خواهیم کرد، یعنی انتظار را پیدا خواهیم کرد:
انواع پراکندگی:
واریانس کلتغییر صفت کل جمعیت را تحت تأثیر همه عواملی که باعث این تنوع شده اند مشخص می کند. این مقدار با فرمول تعیین می شود
میانگین حسابی کل جامعه مورد مطالعه کجاست.
میانگین واریانس درون گروهینشاندهنده یک تغییر تصادفی است که ممکن است تحت تأثیر هر عامل نامشخصی ایجاد شود و به ویژگی-عامل زیربنایی گروهبندی بستگی ندارد. این واریانس به صورت زیر محاسبه می شود: ابتدا واریانس برای گروه های فردی محاسبه می شود () سپس میانگین واریانس درون گروهی محاسبه می شود:
 که در آن n i تعداد واحدهای گروه است
که در آن n i تعداد واحدهای گروه است
واریانس بین گروهی(واریانس میانگین های گروهی) تنوع سیستماتیک را مشخص می کند، به عنوان مثال. تفاوت در اندازه صفت مورد مطالعه که تحت تأثیر عامل صفت که اساس گروه بندی است به وجود می آید.

مقدار متوسط برای یک گروه جداگانه کجاست.
هر سه نوع واریانس با هم مرتبط هستند: واریانس کل برابر است با مجموع میانگین واریانس درون گروهی و واریانس بین گروهی:
![]()
خواص:
25 نرخ نسبی تغییرات
|
ضریب نوسان |
|
|
انحراف خطی نسبی |
|
|
ضریب تغییرات |
|
Coef. Osc Oنوسانات نسبی مقادیر شدید ویژگی را در اطراف میانگین منعکس می کند. رابطه لین خاموش... سهم میانگین مقدار علامت انحراف مطلق از مقدار متوسط را مشخص می کند. Coef. تنوع رایج ترین معیار تغییرپذیری است که برای ارزیابی معمولی بودن میانگین ها استفاده می شود.
در آمار، جمعیت هایی با ضریب تغییرات بیشتر از 30 تا 35 درصد ناهمگن در نظر گرفته می شوند.
منظم بودن سری توزیع. لحظه های توزیع شاخص های فرم توزیع
در سری تغییرات، بین فرکانس ها و مقادیر ویژگی متغیر ارتباط وجود دارد: با افزایش ویژگی، مقدار فرکانس ابتدا تا یک حد مشخص افزایش می یابد و سپس کاهش می یابد. چنین تغییراتی نامیده می شود الگوهای توزیع
شکل توزیع با استفاده از شاخصهای عدم تقارن و کشیدگی بررسی میشود. هنگام محاسبه این شاخص ها از گشتاورهای توزیع استفاده می شود.
لحظه k-امین مرتبه میانگین k-امین درجه انحراف انواع مقادیر ویژگی از مقداری ثابت نامیده می شود. ترتیب لحظه با مقدار k تعیین می شود. هنگام تجزیه و تحلیل سری تغییرات، آنها به محاسبه ممان چهار مرتبه اول محدود می شوند. هنگام محاسبه ممان، فرکانس ها یا فرکانس ها را می توان به عنوان وزن استفاده کرد. بسته به انتخاب یک ثابت، لحظات اولیه، شرطی و مرکزی وجود دارد.
شاخص های فرم توزیع:
عدم تقارن(As) شاخصی که درجه عدم تقارن توزیع را مشخص می کند .

بنابراین، با عدم تقارن منفی (سمت چپ).  ... با عدم تقارن مثبت (سمت راست).
... با عدم تقارن مثبت (سمت راست).  .
.
گشتاورهای مرکز را می توان برای محاسبه عدم تقارن استفاده کرد. سپس:
 ,
,
جایی که μ 3 لحظه مرکزی مرتبه سوم است.
- کشیدگی (E به ) شیب نمودار تابع را در مقایسه با توزیع نرمال در همان قدرت تغییر مشخص می کند:
 ,
,
که در آن μ 4 نقطه مرکزی مرتبه چهارم است.
قانون توزیع عادی
برای توزیع نرمال (توزیع گاوسی)، تابع توزیع به شکل زیر است:


مقدار مورد انتظار - انحراف استاندارد
توزیع نرمال متقارن است و با رابطه زیر مشخص می شود: Xav = Me = Mo
کشیدگی توزیع نرمال 3 و ضریب چولگی 0 است.
منحنی توزیع نرمال یک چند ضلعی است (خط زنگوله شکل متقارن)
انواع پراکندگی. قانون جمع واریانس ماهیت ضریب تعیین تجربی.
اگر جمعیت اولیه بر اساس برخی ویژگیهای اساسی به گروههایی تقسیم شود، انواع واریانسهای زیر محاسبه میشوند:
واریانس کل جمعیت اصلی:
مقدار میانگین کل جمعیت اصلی کجاست؛ f فراوانی جمعیت اصلی است. واریانس کل انحراف مقادیر فردی یک صفت را از مقدار میانگین کل جمعیت اصلی مشخص می کند.
واریانس های درون گروهی:
که j تعداد گروه است؛ مقدار متوسط در هر گروه j است؛ - فرکانس های گروه j. واریانس های درون گروهی انحراف ارزش فردی صفت در هر گروه را از میانگین گروه مشخص می کند. از بین همه واریانسهای درون گروهی، میانگین با فرمول محاسبه میشود: تعداد واحدهای هر گروه j در کجاست.
واریانس بین گروهی:
واریانس بین گروهی انحراف میانگین گروه از میانگین کل جمعیت اصلی را مشخص می کند.
قانون جمع واریانسدر این واقعیت نهفته است که واریانس کل جمعیت اصلی باید برابر با مجموع بین گروهی و میانگین واریانس های درون گروهی باشد:
ضریب تعیین تجربینسبت تغییرات صفت مورد مطالعه را به دلیل تنوع صفت گروه بندی نشان می دهد و با فرمول محاسبه می شود:
روش شمارش از صفر شرطی (روش گشتاورها) برای محاسبه میانگین و واریانس
محاسبه واریانس با روش گشتاورها بر اساس استفاده از فرمول ها و خواص پراکندگی 3 و 4 است.
(3. اگر همه مقادیر صفت (گزینه ها) با مقداری ثابت A افزایش (کاهش) داشته باشند، واریانس جمعیت جدید تغییر نخواهد کرد.
4. اگر همه مقادیر صفت (گزینه ها) با K برابر افزایش (ضرب) شوند، که در آن K یک عدد ثابت است، واریانس جمعیت جدید به اندازه K 2 برابر افزایش (کاهش) می شود.
فرمول محاسبه واریانس در سری های متغیر با فواصل مساوی را با روش ممان بدست می آوریم:

الف - صفر مشروط، برابر با گزینه با حداکثر فرکانس (وسط بازه با حداکثر فرکانس)
محاسبه میانگین با روش ممان نیز بر اساس استفاده از خواص میانگین است.
![]()
مفهوم مشاهده انتخابی مراحل بررسی پدیده های اقتصادی به روش نمونه گیری
مشاهده انتخابی به مشاهده ای گفته می شود که در آن همه واحدهای جمعیت اولیه مورد بررسی و مطالعه قرار نمی گیرند، بلکه تنها بخشی از واحدها مورد بررسی قرار می گیرند، در حالی که نتیجه بررسی بخشی از جمعیت برای کل جمعیت اولیه اعمال می شود. مجموعه ای که از آن واحدها برای بررسی و مطالعه بیشتر انتخاب می شوند نامیده می شود عمومیو تمام شاخص های مشخص کننده این مجموعه نامیده می شوند عمومی.
حدود احتمالی انحراف میانگین نمونه از میانگین کلی نامیده می شود خطای نمونه گیری.
مجموعه واحدهای انتخاب شده نامیده می شود انتخابیو تمام شاخص های مشخص کننده این مجموعه نامیده می شوند انتخابی.
مطالعه نمونه شامل مراحل زیر است:
ویژگی های موضوع تحقیق (پدیده های انبوه اقتصادی). اگر جمعیت عمومی کم باشد، نمونه گیری توصیه نمی شود، مطالعه مستمر ضروری است.
محاسبه اندازه نمونه تعیین حجم بهینه ای که امکان به دست آوردن خطای نمونه برداری در محدوده قابل قبول با کمترین هزینه را فراهم می کند، مهم است.
انتخاب واحدهای مشاهده با در نظر گرفتن الزامات تصادفی، تناسب.
اثبات نمایندگی بر اساس برآورد خطای نمونه گیری. برای یک نمونه تصادفی، خطا با استفاده از فرمول محاسبه می شود. برای نمونه هدف، نمایندگی با استفاده از روش های کیفی (مقایسه، آزمایش) ارزیابی می شود.
تجزیه و تحلیل نمونه اگر نمونه تشکیل شده الزامات نمایندگی را برآورده کند، با استفاده از شاخص های تحلیلی (متوسط، نسبی و غیره) آنالیز می شود.









